
AI 風險管理框架(AI RMF 1.0)是美國國家標準暨技術研究院(NIST)在 2023 年 1 月發布的一份自願性框架。標示「自願」,很多組織就自動歸類為「有空再看」的參考文件。
這個判斷需要重新想想。
NIST CSF(網路安全框架)也是自願框架,但它如今已是全球資安治理的事實標準——從企業董事會到保險核保、從供應鏈採購到監管檢查,都在用它作為衡量組織成熟度的共通語言。AI RMF 的設計邏輯完全一樣:它不是法規,但它正在定義「什麼叫做有在管理 AI 風險」的標準。歐盟 AI Act、白宮行政命令、各國監管機構的指導文件,幾乎都以 NIST AI RMF 作為參照座標。換句話說,現在自願採用,未來很可能就是市場門票。
更關鍵的是,AI RMF 跟傳統軟體風險管理有一個根本性的差異:它把 AI 視為「社會技術系統」(Socio-technical System),而不只是一套軟體。這意味著風險不僅來自技術本身,更來自它與人類行為、社會情境的交互作用。這個定位直接影響了整個框架的設計哲學——你不能只靠工程師管 AI 風險,你需要跨領域的團隊、社會科學的視角、以及持續性的組織文化變革。
AI 的風險,跟傳統軟體到底差在哪裡
在深入框架結構之前,有必要先理解一件事:為什麼 NIST 要專門為 AI 做一個風險管理框架,而不是沿用現有的軟體或資安風險框架?
NIST 在附錄 B 中列出了 AI 相較於傳統軟體的獨特風險特性,以下幾點在實務上特別值得注意。
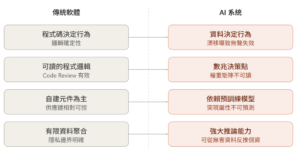
首先是資料依賴與漂移問題。傳統軟體的行為由程式碼決定,邏輯是確定性的;AI 系統的行為由訓練資料決定,而資料會隨時間改變。當部署環境的資料分佈與訓練時期產生偏離——也就是所謂的模型漂移(Model Drift)——系統的表現可能在沒有任何程式碼變更的情況下悄然劣化。這種「無聲失效」是傳統軟體測試方法論幾乎無法覆蓋的。
其次是規模與不透明性。現代 AI 模型包含數十億甚至數兆個決策點,嵌套在更傳統的軟體應用之中。這種規模的複雜度讓「理解模型為什麼做出某個決策」變得極為困難,也讓傳統的程式碼審查(Code Review)失去意義——你審查的是一堆權重矩陣,而不是可讀的邏輯。
第三是預訓練模型的雙面性。使用第三方預訓練模型(Pre-trained Models)可以加速開發、提升精度,但同時引入了統計不確定性、偏見管理的盲點、以及科學可複現性的挑戰。更麻煩的是,大型預訓練模型的突現屬性(Emergent Properties)難以預測——模型在某個規模以下表現正常,超過某個規模後可能出現完全意料之外的行為。
第四是隱私風險的放大。AI 的資料聚合能力遠超傳統軟體,即使個別資料點看似無害,透過 AI 的推論能力,仍然可能識別出個人身份或揭露原本私密的資訊。
這些差異的核心意涵是:你不能用管傳統軟體的方式來管 AI。傳統軟體的風險管理是「寫好規格、做好測試、部署後監控」;AI 的風險管理是一個持續迭代、跨學科、貫穿整個生命週期的動態過程。
三個層面的危害:比你想像的更廣
很多人聽到「AI 風險」,第一反應是「資料外洩」或「模型出錯」。NIST 的定義要寬廣得多——它把 AI 可能造成的危害分為三個層面:對個人的危害(侵害公民自由與權利、身體或心理安全受損、經濟機會受限、針對特定群體的歧視、損害民主參與);對組織的危害(商業營運受阻、財務損失、資安漏洞、聲譽受損);以及對生態系統的危害(全球金融系統動盪、供應鏈中斷、自然資源與地球環境受損)。
這個三層架構的意義在於:它迫使組織在做 AI 風險評估時,視野必須超越自身的營運邊界。一個內部看起來運作良好的 AI 系統,可能正在對外部的個人或社區造成系統性的不公平對待。如果你的風險評估只看技術指標(準確率、延遲、可用性),而沒有考慮社會影響,那你的評估就是不完整的。
可信賴 AI 的七大特徵:不是清單,是權衡
框架定義了可信賴 AI 系統的七大核心特徵:有效且可靠(Valid & Reliable)、安全(Safe)、安全且有韌性(Secure & Resilient)、負責任且透明(Accountable & Transparent)、可解釋且可詮釋(Explainable & Interpretable)、隱私強化(Privacy-Enhanced)、公平且管理有害偏見(Fair – with Harmful Bias Managed)。
這七項特徵的架構設計有一個精妙之處:「有效且可靠」被放在底層,作為其他所有特徵的必要條件——一個不準確的系統,無論多安全、多透明,都不可信賴;「負責任且透明」被放在側面,作為貫穿所有其他特徵的橫向屬性——你可能做到了安全和公平,但如果做不到透明,外部利害關係人無從驗證你是否真的做到了。

在實務中最值得注意的是:這七項特徵之間經常存在權衡取捨(Trade-offs)。隱私強化技術在資料稀疏的情境下可能導致準確度下降,進而影響公平性判斷;追求最大的可解釋性可能犧牲模型的預測精度;高度安全的系統如果不透明,外部仍然無法判斷它是否真的公平。NIST 的立場是:沒有一組固定的配方可以同時最大化所有特徵,你需要根據具體的應用情境做出有意識的、可文件化的權衡決策。
說真的,光是這一點就把很多組織的 AI 治理認知提升了一個層次——從「我們需要確保 AI 是安全的」到「我們需要在安全、隱私、公平、可解釋性之間做出明確的、有根據的取捨,並把這個決策過程記錄下來」。
框架的核心引擎:四大功能
AI RMF 的操作核心由四個功能組成:治理(Govern)、繪製(Map)、衡量(Measure)、管理(Manage)。這四個功能不是線性步驟,而是一個以治理為核心的持續性迭代循環。
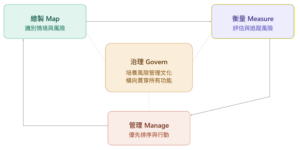
治理(Govern) 是橫向的跨領域功能,不是跟其他三個平行並列的步驟。它貫穿整個 AI 生命週期,涵蓋六大類別:政策與實務的制定(確保與組織風險容忍度一致)、當責機制的建立(角色文件化、團隊培訓、高層承擔決策責任)、多元與包容(決策由跨學科背景的團隊主導)、安全優先文化(鼓勵批判性思考)、多方利害關係人參與(整合外部反饋)、以及第三方與供應鏈風險管理。沒有治理文化支撐的繪製、衡量、管理,都只是形式——就像沒有人維護的機器,偶爾跑一次,大多時候放著生灰。
繪製(Map) 的核心任務是在衡量或管理風險之前,先建立深厚的情境知識。它包含五個步驟:建立情境(定義預期用途、商業價值、使用者類型與法律期望)、系統分類(記錄任務方法、系統限制與人類監督需求)、評估能力與成本(權衡潛在效益與非貨幣成本,如 AI 錯誤造成的影響)、繪製風險圖(識別所有組件中的風險,包括第三方合規與智財風險)、影響描述(評估潛在危害對個人、群體與生態系統發生的可能性與規模)。完成 Map 之後,組織應該有足夠的資訊做出一個初步的「Go/No-Go」決策——是否應該啟動這個 AI 專案。
衡量(Measure) 運用量化、定性或混合方法來分析已識別的風險。四個重點是:選擇適當方法(針對最高優先級風險確定具體指標,並經過獨立審查)、評估可信度(在真實部署條件下測試有效性、可靠性、安全性、隱私與公平性)、追蹤機制(定期追蹤突發風險,並建立終端使用者的反饋循環系統)、效能評估(使用現場實際數據,持續監控 AI 系統相對於基準線的表現)。值得注意的是,當可信度特性之間出現衝突時,衡量能提供資料支持管理決策——不是自動告訴你該怎麼做,而是讓你有數據基礎去做有意識的取捨。
管理(Manage) 將資源精準分配給已繪製與衡量的風險。它是一個從排序到行動、從策略到復原的完整鏈條:風險優先排序(依據衡量出的影響,決定是繼續推進、緩解、轉移、避免或接受風險)、制定應對策略(必要時實施非 AI 替代方案,並建立覆寫或停用不安全 AI 系統的機制)、第三方風險管理(持續監控來自預訓練模型與外部資料的風險)、處理與復原(執行部署後監控、變更管理、事件回應,並透明地溝通系統錯誤)。
TEVV:不是部署前打勾一次,而是全生命週期的持續生命線
測試、評估、驗證與確認(TEVV)在框架中的定位非常明確:它不是一個獨立階段,而是貫穿整個 AI 生命週期的持續性活動。
關鍵的觀念是:TEVV 允許在整個生命週期中進行中段修復與事後風險管理。它不是部署前打勾一次的核取方塊,而是一條持續運作的生命線。
設定檔(Profiles):讓框架不停留在理論
框架不規定單一模板。組織透過建立「設定檔」,將框架的類別與子類別對應到特定的應用場景、產業或時間點。設定檔分為兩種:現有概況(Current Profile)描述組織目前在 AI 風險管理上的真實狀況;目標概況(Target Profile)描述符合法律、法規與道德最佳實務的期望成果。
兩者的比較會揭示差距(Gap),而差距分析會驅動具體的行動計畫——需要哪些預算、人力、流程變革,以及行動的優先順序。值得注意的是,框架還提出了「跨部門剖析(Cross-Sector Profiles)」的概念,用來應對如大型語言模型(LLMs)或雲端 API 等廣泛使用的通用技術風險。
AI 系統生命週期與多元行動者的集體責任
NIST 採用了 OECD 的框架,將 AI 系統的生命週期分為五個關鍵社會技術維度:應用情境(Application Context)、資料與輸入(Data and Input)、AI 模型(AI Model)、任務與輸出(Task and Output),以及位於中心的「人與地球」(People and Planet)。
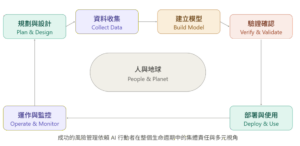
每個維度都有不同角色的 AI 行動者(AI Actors)——從資料科學家、領域專家、社會文化分析師,到合規專家、終端使用者、受影響的社區。NIST 特別強調的一點是:建立和使用模型的人與驗證和確認模型的人,應該是分開的——這是一項最佳實務分離原則,目的是避免開發者的認知偏見影響測試結果。
成功的風險管理不是某個團隊的工作,而是所有 AI 行動者的集體責任。這需要多元的人口結構、學科背景與經驗——因為多元團隊更能揭露隱含的假設、發現潛在的風險盲點,以及識別系統在不同社會情境中可能產生的非預期影響。
風險管理的四個挑戰:為什麼這件事特別難
框架也坦承,AI 風險管理面臨四個結構性挑戰。
風險衡量方面,第三方資料與軟體帶來隱含風險,目前缺乏共識性的可靠風險指標,而且突發風險(Emergent Risks)本質上就難以用現有方法量化。風險承受度方面,不同組織、應用案例與法規環境對風險的容忍標準完全不同——這高度依賴情境,沒有通用答案。風險優先排序方面,試圖完全消除風險是不切實際的,資源必須依據潛在影響的嚴重性(特別是生命安全威脅)進行分配。組織整合方面,AI 風險不能孤立存在——它必須與現有的企業風險管理(ERM)、資安與隱私策略深度整合。
這四個挑戰的共同指向是:AI 風險管理不是一個可以「完成」的專案,而是一個需要持續投入、持續校準的組織能力。
實施框架的預期成果
NIST 列出了成功實施 AI RMF 之後,組織應該能夠達成的幾項成果:強化 AI 風險繪製、衡量與管理的清晰流程;提升對「社會技術方法」及可信度權衡的認知;建立更明確的系統測試與部署「Go/No-Go」決策點;建立優先識別風險的組織當責文化;以及增強跨部門、利害關係人之間有關突發風險的資訊共享與溝通。
從趨勢來看,AI RMF 的真正價值不在於它提供了一份清單讓你打勾,而在於它為 AI 治理提供了一套共通的語言和思維框架。當你的組織、你的供應商、你的監管機構都在用同一套語言討論 AI 風險時,對話的效率和深度會有質的提升。
最後,有一個值得記住的觀念:AI RMF 是一份「活文件」(Living Document)。它自願性、維護人權、非特定產業,需要所有 AI 行動者的集體承諾。NIST 計畫不遲於 2028 年進行一次正式的社群審查與更新。創新與風險防範並不衝突——負責任的實踐將確保 AI 科技嘉惠社會,同時將潛在危害降至最低。
本文觀點來自個人心得與觀察,不代表任何組織或機構立場。
參考資料來源:NIST AI 100-1 Artificial Intelligence Risk Management Framework (AI RMF 1.0), January 2023